
迭代式MapReduce解决方案(一)
一、迭代式Mapreduce简介
普通的MapReduce任务是将一个任务分割成map与reduce两个阶段。map阶段负责过滤、筛选、检查输入数据,并将处理后的结果写入本地磁盘中;reduce阶段则负责远程读入map的本地输出结果,对数据进行归并、分析等处理,之后再将结果写入HDFS中。其数据流过程如下:
(k, v) -> map -> (k1, v1), (k1, v2), (k2,v3) -> sort&shuffle -> (k1, list(v1, v2)), (k2, v3)
而迭代式的MapReduce任务需要迭代执行以上过程多次,由于每次任务都是独立的,则需要不断的读取、写入、传输数据,如果还是按照普通的MapReduce一样运行MR任务,性能将会非常低下。
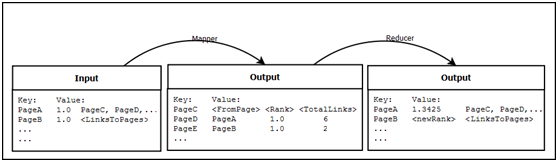
本文拿PageRank做一个例子,PageRank是Google的网页排名算法,是基于网页与网页之间的链接关系计算而得,计算过程需要不断的迭代(单次MR任务),获取一个新的PR值后,再继续迭代,直到两次迭代之间的PR差值小于某一个阈值即停止。
PageRank计算数据分为两个部分:
| URL | RANK | URL | OUT_LINK |
|---|---|---|---|
| www.a.com | 1 | www.a.com | www.b.com |
| www.b.com | 1 | www.a.com | www.c.com |
| www.c.com | 1 | www.b.com | www.a.com |
| www.d.com | 1 | www.b.com | www.c.com |
| www.c.com | www.d.com | ||
| www.d.com | www.b.com | ||
| PR值表 | - | 网页链接关系表 | - |
二、问题分析说明
迭代式作业的缺点很突出,在这篇博客有详细的介绍,本篇主要需要解决的问题是:如何减少不必要的数据传输与读写。
正如前面所示,PageRank的计算数据分为了两种:PR值表以及网页链接关系表。其中PR值是随着迭代而不断变化,称之为动态数据;而网页链接关系,在计算中,不会有任何的改变,称之为静态数据。
我现在能想到的,再参考了网上的实现方式,基本上都是将静态数据与动态数据合并成一个文件,同时读入(mapper)->写出(mapper)->传输(reducer)->写出(reducer)。
我们可以来估算一下时间,先不考虑磁盘IO,仅算静态数据传输时间一项。其中模拟实验数据为:100w个链接地址;随机生成最多1000个外链;结果数据3.22G(动态数据8.5M);实验环境网络带宽100M;迭代次数20次。
单轮迭代,3.22G的数据会从mapper中读入再全部写入到本地磁盘,reducer再从mapper中将3.22G的临时数据传输到相应的taskTracker上。100M带宽的网络,传输速率约为10M/s,计算公式即为:3.22G×1024 / 10 = 330s = 5.5min。迭代20次,5.5×20 = 110min = 1.8h。简单的估算一下,3G左右的数据,在百兆带宽的网络环境,仅静态数据传输这一项就会占去近两小时(这是最坏情况,不考虑数据在本地的情况)!而网页数据远远不止3.22G,如果到了TB乃至PB级的话,耗时应该就不是开发者所能接受的了。
三、问题解决方法
为了减少不必要数据的传输与读写,开发者就一定要做到以下几点:
- 将静态数据与动态数据分离,但需要保证在一次(以及下一次)迭代中,结合动静数据;
- 输出结果中尽量减少数据量,原则上只能有动态数据,不能包含静态数据。
每次map过程中,都需要读入一行PR值表元组,同时也要读入多行对应的链接关系表元组,虽然在map中无法控制两个分离文件的读入顺序,但我们可以预先将动态数据加载进内存作为索引,读入一行后,再查找内存获取需要的数据。这样的方式很容易的就可以想到分布式缓存技术,先前我还在考虑是用Memocached还是Redis,但多看看后好像是多此一举了。MapReduce自带了Distributed Cache技术,可以参见《Mapreduce API文档》。
Haoop中自带的分布式缓存,即DistributedCache对象,可以方便map task之间或者reduce task之间共享一些信息,缓存数据会被分发到集群的所有节点上。需要注意的是,DistributedCache是read-only的。
操作步骤:
- 将数据分发到每个节点上:
DistributedCache.addCacheFile(new Path(args[0]).toUri(), conf);
- 在每个mapper上获取cache文件,便可加载进内存:
DistributedCache.getLocalCacheFiles(conf);
- Reducer写出动态数据,下一次迭代中,再将新的动态数据加载至DistributedCache中。
将动态数据作为缓存文件的后,整个迭代过程,只有大量减少磁盘IO,且在很大程度上减少了网络带宽负荷与无效数据传输时间。
四、总结
以上的方法理论上支持大多数迭代式Mapreduce模型,如pagerank、SSSP(Single Source Shortest Path)等。参考: 董的博客,再加上自己的实践,提出以下一些问题:
(1) 每次迭代,如果所有task重复重新创建,代价将非常高。怎样重用task以提高效率(task pool)?
说明: hadoop自身提供了task JVM reuse的功能。不过该功能仅限于同一个Job内,而我们每次迭代都会重新运行一个job,故自带功能不适用(或者我还不会用)。但是我们可否考虑job复用呢?
(2) 何时迭代终止,怎样改变编程模型,允许用户指定合适终止迭代。
说明:就PageRank来说,迭代中止的条件是每次迭代结果相差小于一个阈值,即PR结果达到平衡。我们就可以将前一次结果直接输出到Reducer中,或者可以从DistributedCache读取前一次PR值,并做判断。
但是一个PR结果符合条件并不能说明任务就结束了,需要所有的(或者说大多数)的结果均满足条件才能中止任务。那么,这个大多数结果满足条件的数据该怎么存放以及读取呢?还有就是,怎么找到一个通过的编程模型去适应其它的迭代式MR任务呢?
(3)就算没有静态数据,动态数据生成也不小
100W行数据3.22G,64M的split有52个,每个2W行数据。由于是随机生成的,平均每行500个链接地址,每个连接地址都会生成一行临时结果<URL_ID AER_PR>,估算一下也有150M(实际140M),那么3.22数据,最后生成临时数据为7G+。
如不加任何优化的话,那铁定是不行的。后面的文章再说说优化问题,在这个实验环境下,可将7G的文件压缩到不到300M。
(4)DistributedCache API的使用
一直觉得Hadoop的版本管理十分混乱,新旧API杂乱,文档不更新!所以DistributedCache API一直没用好,到时候整理一下,顺带说说如何添加第三方jar包。
以上的讨论还待我的继续研究了,性能分析比较以后的文章给填上。如对迭代式MapReduce任务感兴趣的童鞋可以参考一下Apache开源项目Mahout,还有Google的一篇论文<Pregel: A System for Large-Scale Graph Processing>:中文;英文。
参考资料: