
迭代式MapReduce解决方案(三)
1、前言
前面两篇(一)(二)解决方案分别从静态数据(Invariant Data)分离以及分布式缓存来优化迭代式Mapreduce,但是由于Mapreduce天生的缺陷,再加上分布式缓存是分布存放在本地磁盘的,没有一个好的读取方案的话,就会大大提高了每个task的磁盘IO次数。这篇博客算是迭代式Mapreduce的收尾了,来整体分析一下我的解决方案和Haloop方案吧。
2、现存框架的缺陷&我的方案
Haloop发布的文献中,说了两个缺陷,再加上董的一个,共仨:
1)动静态数据无法分离,浪费大量资源(磁盘IO,网络带宽,CPU时间),Haloop原文:The first problem is that even though much of the data may be unchanged from iteration to iteration, the data must be re-loaded and re-processed at each iteration, wasting I/O, network bandwidth, and CPU resources。
我的解决方案:利用分布式缓存来缓存动态数据,可以有效的减少临时数据大小,大量的减少网络带宽压力(10G->0.25G)。但是,通过我的方案,磁盘IO虽然有所下降,但是仍然有待加强的地方,因磁盘IO主要集中在了map task的read阶段,而在坏的情况下,有可能会从其它node远程读取。Haloop修改了一下这种方式,我待会儿说方法。
2)没有一个客观的停止迭代的标准,Haloop原文:The second problem is that the termination condition may involve detecting when a fixpoint has been reached。
我的解决方案:这个方案没有写成博客,因为觉得太普通了。和大多数应用一样,开启一个新的任务,来计算两次迭代之间的差别,Pagerank计算两次迭代过程之间所有页面PR差之和,SSSP计算所有点的状态。但是需要注意的是,由于一个文件就会开启一个map task,所以需要动脑筋思考一下如何“合并”起来。
3)每次迭代,如果所有task重复重新创建,代价将非常高。怎样重用task以提高效率(task pool)。这个缺陷是董的博客提出的,这个虽然没有在Haloop中单独提出,但是实现中已经考虑到了。这个在现有框架下,基本是上没可能了,迭代式Mapreduce需要解决的是Job复用的问题,整个task pool就得修改框架了。
3、Haloop解决方案
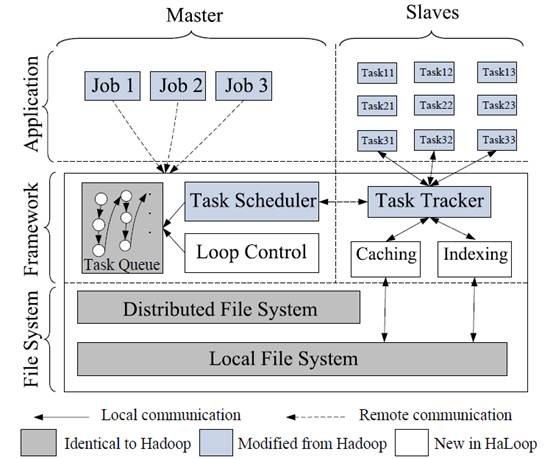
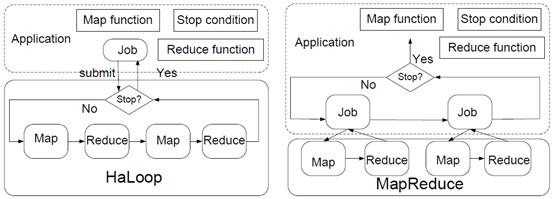
Haloop进行的改进有:
1)提供了一套新的编程接口,以方便用户进行迭代式程序开发
Haloop提供了一些有用的方法,如下:
- SetFixedPointThreshold:设置两次迭代的终止条件,即距离差是否达到某一个阈值
- ResultDistance:计算两次距离的方法
- setMaxNumOfIterations:设置迭代次数
- setIterationInput:设置变化的输入数据
- AddInvariantTable:设置不变的输入数据
有了上面的方法,整个迭代式MR过程很清晰,确实提供了很大的方便。
2) master node(jobtracker)包含一个循环控制模块,它不断的启动map-reduce计算知道满足迭代终止条件
从Haloop计算流程图可以看出,Haloop基本实现了job“复用”,只有一个job就可以了,它可以开启多个map/reduce对,而传统的每次迭代过程都需要开启一个job,且一个job只有一个map/reduce对。且迭代终止条件控制在job内部,无需再启新job来计算。
3)设计了新的Task Scheduler,以便更好的利用data locality特性
Haloop有一个Loop-aware 任务调度机制。Haloop在首次迭代时会将不变的输入数据保存到相应计算节点上,以后每次调度task,尽量放在固定的那些节点上(locality)。这样,每次迭代,不变的数据就不必重复传输了。
4)数据在各个task tracker会被缓存(cache)和建索引(index)
Map task的输入与输出,Reduce task的输出都会被建索引和缓存,以加快数据处理速度。这个部分在论文中占的大量份额,所以我也没有仔细看,整体来说就是和分布式缓存有异曲同工之妙。需要说明的是,缓存是指数据被写到本次磁盘,以供下一轮循环迭代时直接使用,Haloop也并没有完全存入内存,应该是担心内存不够使的。
4、总结
迭代式Mapreduce还有待继续研究,按照董的说法,haloop模型抽象还不够高,支持计算模型有限,而现有的解决方案都不是最优的。我所提出的方案只是在不修改源码的情况下,最大限度的优化计算过程,还是不够优!不过Yahoo!要推出下一代的Mapreduce,从它发表的文章来看,解决迭代式问题好似有戏,可以参考这里:The Next Generation of Apache Hadoop MapReduce。
参考资料
>