
MapReduce优化(一)
一、概述
这篇博文主要是解决上一篇迭代式MapReduce解决方案(一)中总结所提到的第三个问题,与网上大多数Hadoop调优(董的博客;、淘宝数据平台)不太一样,网上告诉的是方法,但是方法是什么以及优化后能达到什么效果没有一个直观的感受。这篇博文讲述了一些简单的优化手段,可将140M的临时文件缩小到4.9M,期望能有一些对优化一些更为直观的感受,起到抛砖引玉的作用。
二、问题的提出
用的例子依然是上篇博客讲到的PageRank计算,其中输入数据为随机生成的100W行记录,大小3.22G。我们也可以来粗略的估算一下,单个map task生成的临时文件大小:
3.22G数据,100W记录。每行平均32kb,一个split为64M,约2W行数据。由于是随机生成的数据,所以每行平均约为500个外链地址,每个连接地址都会生成一行临时结果
而实际上,在不进行任何优化的情况下,一个map task生成的临时文件为140.6M,很大的结果啊!
三、优化方案
1、设置combiner
Mapreduce中的Combiner就是为了避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。
对于Combiner有几点需要说明的是:
1)有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
2)与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
3)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
4)一般来说,combiner即reducer,它们俩进行同样的操作。
对于PageRank计算来说,单个reduce操作即对值求和,适用combine操作。添加代码如下:
1 | job.setCombinerClass(PRReducer.class); |
最后输出结果大小28.3M,“压缩”比约为20%。
2、数据压缩
顾名思义,对输出结果进行压缩,Hadoop称之为codec。下面列举一些常见的codec:
| 压缩格式 | HadoopCompressionCodec |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
以下两行代码即可:
1 | conf.setBoolean("mapred.compress.map.output", true); |
但需要注意的是,时间与空间永远是矛盾的,若要获得大的压缩比就会降低一些时间效率。通常来说,想要达到cpu和磁盘压缩比的平衡取舍,LzoCodec比较适合。不过由于GPL许可的原因,该库没有包含在Apache的发行版中,需要单独从Google Code或GitHub下载,其中后者包含有修正的软件错误及其它一些工具。
本文使用的是默认的压缩方式DefaultCodec,压缩比约为29%。
3、查看临时文件内部,具体情况具体分析
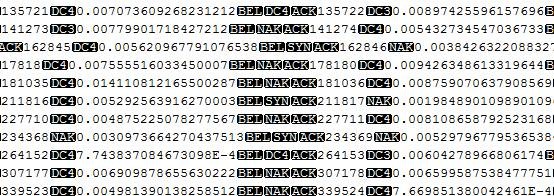
上面的文件就是我的临时文件内部格式, value在内存中为DoubleWritable,没有考虑精度问题。一个value数据输出后,就会占20字节,我们是否需要这么高的精度呢?
我觉得是不需要,不需要的话,就是将输出数据精度降低,实验中将double精度降至6位,“压缩”比约为59%。这个例子很实在,即对于每个任务来说,不仅仅是job conf需要优化,其自身算法或者说数据格式都还有很大的优化空间。没有最好,只有更好!
四、总结
经过上面几个“简单”的优化,代码行数修改寥寥几行,临时数据从140.6M降到了4.9M,压缩比为3.49%。需要注意的是,实验所用数据是模拟的,且数据分布较为均匀,故在实际生产环境中压缩比应该没这么高,所以需要根据job的实际情况,选择combine、压缩、数据格式,但其所带来的优化结果仍会很可观。
本文只是简要的抽出了一些方便做实验的优化方法,更多的更广的配置、代码优化方法,敬请期待以后的博文。
参考资料:
- hadoop作业调优参数整理及原理
- Hadoop权威指南