
Hadoop Pipes运行机制
1、前言
Hadoop Pipes可供C++开发者开发MapReduce任务。文献与书籍上也写了,C++与Java是通过Socket通信,但是具体的运行机制是什么还是得参考源码。
这篇博文主要从源码角度来讲解Hadoop Pipes运行机制以及设计原理,实际的Hadoop Pipes编程请参见:Hadoop Pipes编程
2、Hadoop Pipes运行图解
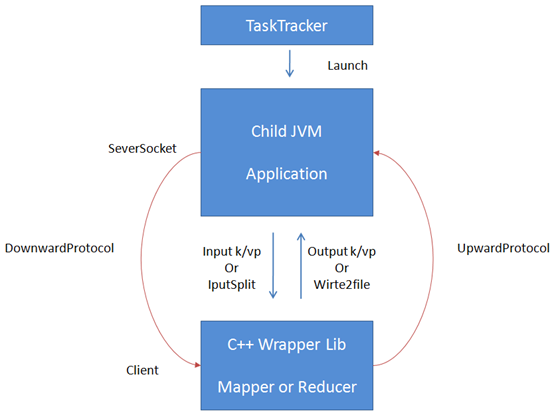
3、Hadoop运行机制
Hadoop端主要类均在org.apache.hadoop.mapred.pipes包下,见下图。
其中,Application是JVM中主要运行程序,PipesMapRunner、PipesReducer、PipesPartitioner、PipesNonJavaInputFormat分别对应C++版的Mapper、Reducer、Partitioner、RecordReader,由于重写RecordWriter后,C++会直接写文件,这里就没有对应的类了。DownwardProtocol/BinaryProtocol、UpwardProtocol/OutputProtocol是Java与C++交互的接口代理类。
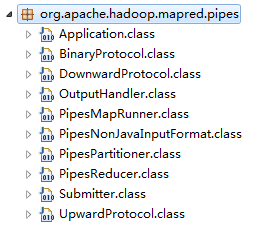
开发者通过$HADOOP_HOME/bin/hadoop pipes将作业提交到了包下的Submitter类。运行过程就直接贴文字了,可以结合代码一起看:1
2
3
4
5
6
71 解析命令行参数
2 setupPipes(job)
2.1 设置Mapper,Partitioner,Reducer,RecordWriter,如果不是java编写的,则用PipesMapRunner,PipesPartitioner,PipesReducer,NullOutputFormat(所有输出均输出到/dev/null中);
2.2 设置map/reduce的key/value class,均为Text.class;
2.3 设置RecordReader,如果不是java编写的,则用PipesNonJavaInputFormat;
2.4 获得运行程序,debug脚本以及缓存文件;
3 JobClient.submitJob(job);
JobClient提交任务和非Pipes编程提交过程一致,进行Task调度分配之后,就会在分配的TaskTracker上开启JVM进程,运行Runner。这里解析一下PipesMapRunner的运行机制:
1 | 1 创建Application |
2 如果不是Java编写的RecordReader,直接发送一个InputSplit(注:只是Split的信息,不包括文件数据)给客户端;反之,发送InputSplit之后,再循环读取split,将record格式化之后,将KVP发给客户端。
1 | 1 创建Application,与Map一致; |
以上是Hadoop端的运行机制,C++端的与Java的也基本一致,源文件在$HADOOP_HOME/src/c++/pipes/impl/HadoopPipes.cc
在组件运行时,会用ProcessBuilder运行C++可执行文件,可执行文件的main程序基本上都是这样写的:
1 | int main(int argc, char *argv[]) { |
调用了HadoopUtils::runTask(factory)方法,运行机制如下:
1 | 1 创建运行环境; |
4、Hadoop Pipes浅析
Hadoop Pipes采用类RPC机制,封装了Hadoop端与C++端的调用接口。Hadoop调用C++的协议为DownwardProtocol,C++调用Hadoop的为UpwardProtocol。同时也封装了传输数据序列化的接口(SerialUtils.cc),代码结构十分清晰。
但是实际使用中也有一定缺陷,调试起来十分麻烦。C++端挂了之后,Hadoop也就接受不到的心跳消息,所以错误一律为:Pipes Broken。Apache的维基上有一个条目:howToDebugMapReducePrograms,改天得好好研究一下。
参考资料:
Hadoop源码