
发现Hadoop小bug一枚
最近在做一个任务,合并大小文本文件,每个不到5M,合并之后再进行统计分析。但是统计分析结果不对,本来只有60w个文件,但是最后的结果竟然到了200w了,断断续续debug了几天,从合并、map过程、combine过程、reduce过程,都一一过了一遍。最后发现在map过程中的数据就有重复,而且重复的形式很奇怪。
举例来说,SequenceFile中两个记录一个4M一个为1M,map第一个4M的记录没出现问题,但是map第二个1M的记录出问题了,记录大小为1M,但是getBytes()之后会获得4M的数据,前面1M是正常数据,而后面3M是非法的前一个记录的后3M数据。
开始以为是jvm没有将内存给销毁,但是觉着不对劲,就直接跟进代码瞅了瞅几眼。原来在map过程中,每次获得的key和value均会复用,而不会销毁,而Text的数据均存在了一个bytes数组,Text对象不销毁,bytes数组也不会销毁。可以参见:LineRecordReader or SequenceFileRecordReader的nextKeyValue()方法,该方法由Mapper的run方法间接调用。
继续刚才的那个问题,我在读取Text中的数据时,会调用text.getBytes()方法,逻辑上它应该是要返回length长度的bytes给开发者,但是它却将整个bytes数组返回了。
心想着可以提交一个patch,但后来翻了一下新版本的源码,发现hadoop已经提供了一种解决方案——copyBytes()。具体实现见下图:
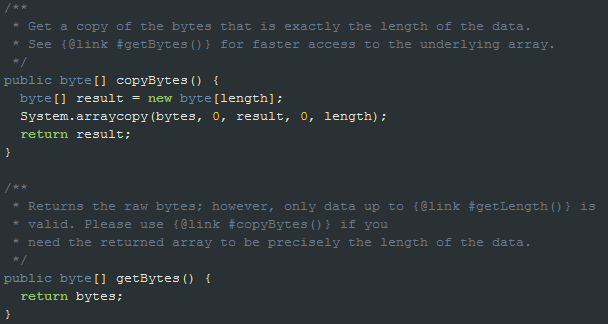
Hadoop会在不变动原有逻辑的基础上进行修改,这样的话可以最大限度的减少对用户的影响,并且可以往下兼容。值得学习啊,给我的话,就直接修改getBytes()方法了。
我是基于0.20.203.0做的实验,这个问题在0.22之后的版本均提供了解决方案。