
Map/Reduce Task源码分析
1、序言
这篇文章从十一前开始写,陆陆续续看源码并理解其中的原理。主要了解了Map/Reduce的运行流程,并仔细分析了Map流程以及一些细节,但是没有分析仔细Reduce Task,因为和一个朋友@lidonghua1990一起分析的,他分析ReduceTask,这篇文章的Reduce的注释部分也是由他添加。等到他分析完Reduce之后,再将链接填上。
2、源码流程分析
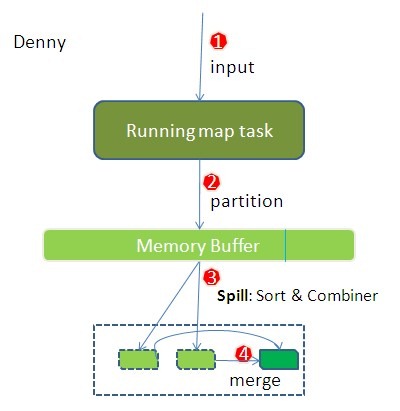
1 | -----------------------------Start----------------------------------- |
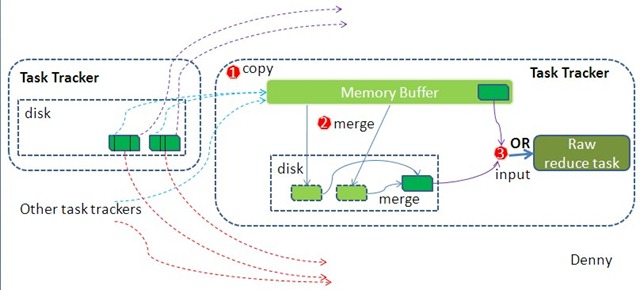
1 | ----------------------Tmp Data(On disk)------------------------------- |
3、部分问题分析
1)如何排序并输出的?
sortAndSpill();
mapper接收到map端的输出后,会将所有的输出数据写入一个缓存中,当缓存大小超过一定阈值的时候,就会锁住部分数据,将这些数据写入磁盘中。没被锁住的数据则可继续写入,不受写操作影响。阈值等于io.sort.mb(100MB) * io.sort.spill.percent(0.8)。
缓存采用的circle buffer,看似简单,但是hadoop中还是会有点小技巧,详细的可以看caibinbupt的博客(分析1,分析2),里面比较详细。
缓存一般是用byte数组存,因为这样可以严格控制缓存大小。当然,如果记录大小一致的话,可以开相应的对象数组。但是,map中的缓存kv数据大小不一致,这样要排序的话,就会有很多问题:
如何快速定位其中的排序键;定位了快速键之后,由于记录大小不一,原地排序会带来大量的数据交换。
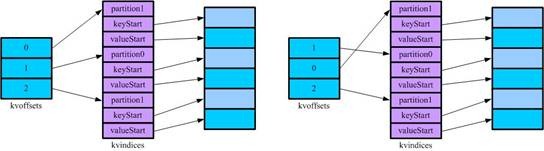
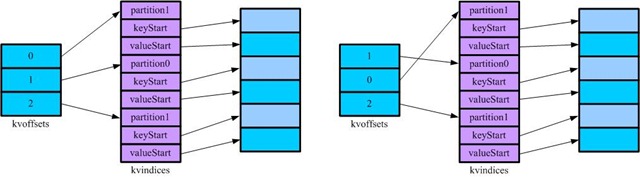
为了避免这样的问题出现,mapreduce实现中提供了两个索引记录,第一个为kvindices(kvpair1[partion1, key1_start, value1_start], kvpair2[partition2, key2_start, value2_start]),这个索引指向缓存中记录的起始位置;第二个为kvoffsets,记录kvindices中kvpair的位置,只需要比较kvoffsets中所对应的partition值以及key值再交换kvoffsets中的值即可完成排序。
2)combine什么时候执行的?
- 在map端内存溢写到磁盘的时候会执行combine(可配置不执行,min.num.spills.for.combine默认为3,当spill数少于3的时候,就不会执行);
- 在map端合并磁盘溢写文件的时候会执行combine;
- 在reduce端合并内存拉取文件的时候会执行combine(inMemFSMergeThread)。
为什么在localFSMergerThread中不执行combine呢?因为这个时候执行的combine就是reduce过程了。
3)segment和group是啥?
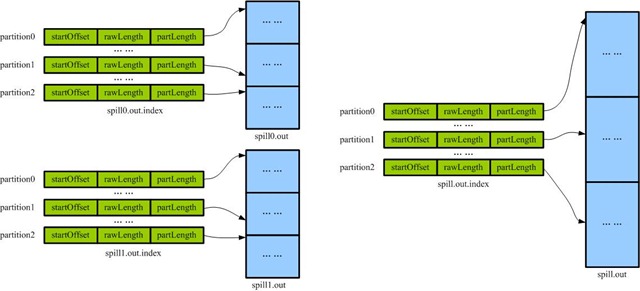
segment
每个map端划分出来的partition所对应的数据块为一个segment。如下,partition0/1/2所对应spill.out的一段数据均为一个segment。
即segment是map端merge spills,以及reduce端merge从map端copy过来的数据的逻辑单元。
个人理解就是reduce端进入一个reduce()方法的数据称之为一个group。默认按key分组。一般来说,用户涉及到group也就是二次排序的时候需要用到,因为需要自定义分组。可以参见《Hadoop权威指南》第8章的辅助排序。
4)如何合并文件?
Map阶段的合并发生在spill完所有文件之后,而Reduce阶段则发生在copyPhrase结束之后,两者逻辑是一直的,所以hadoop将合并写成了通用组件,即Merger。在分析Merger的前,需要了解segment(Merger$Segment)的概念,可以参见前文。
将合并过程简单化:即有一些已经排好序的文件(Segment),需要对其进行合并并排序。需要和解决方案都很明显,用多路归并排序。
Merger类实现了一个merge方法,该方法生成了一个MergeQueue实例,并调用了该实例的merge方法。MergeQueue继承了PriorityQueue。归并排序的时候需要取多个文件的最小值,hadoop实现是采用的小根堆,比较方法是Merger中的lessThan(a,b),它会读取segment中当前key,并使用用户自定义类的comparator进行比较。归并路数根据io.sort.factor(10)设置。
5、我之前的的认识误区
1)map输出记录格式是怎样的?
map的输出为:(key1, value1); (key1, value2); (key1, value3),而不是:(key1, list(value1, value2, value3)),这个只是逻辑上的格式。
为什么这样呢:
猜测: 一个key对应的list过大的话,内存放不下;不如来一条记录,输出一条记录。所以如果设置了combiner的话,最后对数据的压缩是很可观的。
2)是否可以将mr中的临时数据不写入磁盘?
从源码的角度来说,是不可能的。可以考虑Spark以及Storm的实现。
6、参考资料
《hadoop权威指南》
源码版本 0.20.203.0