
记一次java性能问题定位
1、前言
前一段时间检查集群状态时,发现某部分机器的load较高,故登录服务器查看,某几个java进程的cpu使用率为1000%,没见过这么高的cpu时间,顿时就长见识了!长完见识问题还是要解决的,故本文记录下问题定位的过程。
2、定位流程
2.1 定位问题进程
top命令可以简单定位进程pid,如下:

jps -vm | grep 15195 可以查看java进程的参数或者日志地址等,如果没有显示参数的话,可以cd到/proc/15195/cwd目录,该目录便是进程的运行目录。
2.2 查看日志
常规做法就是查看日志了,但是扫了几遍日志也没发现问题,因为这个进程这几天的请求都不是很多,难道是线程空转了?
2.3 定位问题线程
既然日志没有发现异常,那只是通过查看进程内部发现问题了。man top可以看到top命令的详细信息,-H则是线程开关,传入该参数的话,top界面会显示所有单独的线程列表。
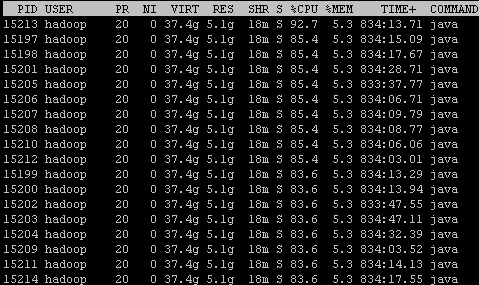
不看不知道,一看吓一跳啊,cpu跑满的线程挺多的,第一列便是他们的线程id。
2.4 Thread dump
拿到异常的线程id后,便可以将该进程的线程栈全部输出了,用到的工具是jstack。
jstack 15195 > jstack.15195.dump
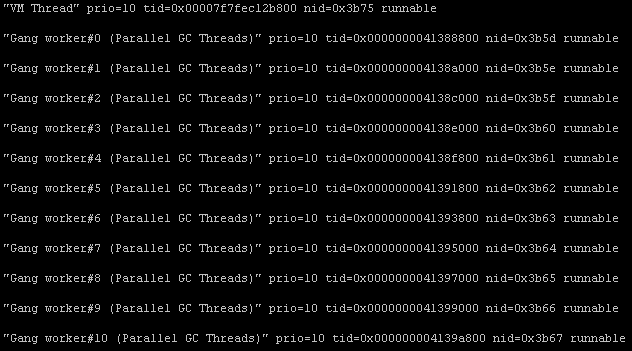
快速搜索的话,可以直接拿pid转换成16进程定位,当然,也可以慢慢看那些线程处于RUNNABLE状态,不过定位问题较慢。
通过查询异常线程pid,发现所有的都是Parallel GC Threads,实在是太奇怪了。
2.5 查看gc状态
jstat -gc 15195 获得当前进程的gc状态,会发现该线程在不断的进行FullGC操作:


短短几分钟,就FGC了28次!初步定位问题为FGC问题。
注:用jstat -gcutil $PID $INTERVAL $TIMES查询可能会更直接,我查到这里应用被停止了,就木有现场了。
3、问题解决
现在出现的问题就是表现在了full gc次数频繁,从上面的应用而言,可以发现PU(PermGen Usage)占用非常高,约为95.7%。由于Perm代过高,且CMS GC无法回收掉Perm区内容,而导致频繁GC。
CMS GC与普通的STW Full GC不同,不会暂停应用,但是会导致CPU使用率非常高。
解决方法有两种:
- 提高Perm区大小,-XX:PermSize -XX:MaxPermSize
- 关掉Perm区收集机制,取消-XX:+CMSClassUnloadingEnabled
这里有关于Perm区GC时机的深入且详细的解释,http://rednaxelafx.iteye.com/blog/1108439