Netty 4.x学习笔记 - ByteBuf
1、前言
程序员喜欢说一句话:「不要重复造轮子」,但是程序员又不太会践行这句话。这倒也不是坏事,程序员一般而言看他人代码都不会太爽,这也可能是导致程序员的世界有各式各样的轮子的原因吧。
2、ByteBuf与Java NIO Buffer
ByteBuf则是Java NIO Buffer的新轮子,官方列出了一些ByteBuf的特性:
- 需要的话,可以自定义buffer类型;
- 通过组合buffer类型,可实现透明的zero-copy;
- 提供动态的buffer类型,如StringBuffer一样,容量是按需扩展;
- 无需调用flip()方法;
- 常常「often」比ByteBuffer快。
3、ByteBuf实现类
ByteBuf提供了一些较为丰富的实现类,逻辑上主要分为两种:HeapByteBuf和DirectByteBuf,实现机制则分为两种:PooledByteBuf和UnpooledByteBuf,除了这些之外,Netty还实现了一些衍生ByteBuf(DerivedByteBuf),如:ReadOnlyByteBuf、DuplicatedByteBuf以及SlicedByteBuf。
ByteBuf实现类的类图如下:
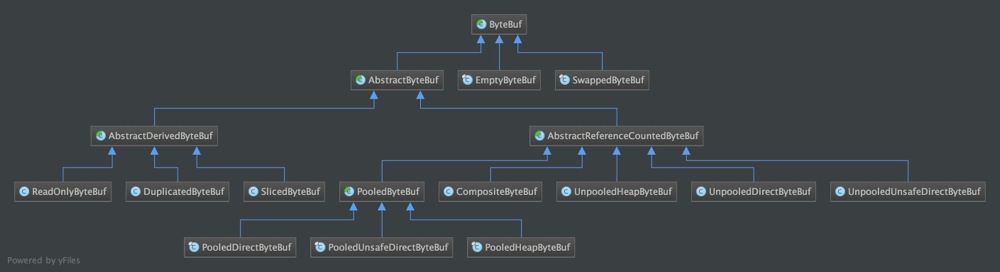
HeapByteBuf和DirectByteBuf区别在于Buffer的管理方式:HeapByteBuf由Heap管理,Heap是Java堆的意思,内部实现直接采用byte[] array;DirectByteBuf使用是堆外内存,Direct应是采用Direct I/O之意,内部实现使用java.nio.DirectByteBuffoer。
PooledByteBuf和UnpooledByteBuf,UnpooledByteBuf实现就是普通的ByteBuf了,PooledByteBuf是4.x之后的新特性,稍后再说。
DerivedByteBuf是ByteBuf衍生类,实现采用装饰器模式对原有的ByteBuf进行了一些封装。ReadOnlyByteBuf是某个ByteBuf的只读引用;DuplicatedByteBuf是某个ByteBuf对象的引用;SlicedByteBuf是某个ByteBuf的部分内容。
SwappedByteBuf和CompositedByteBuf我觉得也算某种程度的衍生类吧,SwappedByteBuf封装了一个ByteBuf对象和ByteOrder对象,实现某个ByteBuf对象序列的逆转;CompositedByteBuf内部实现了一个ByteBuf列表,称之为组合ByteBuf,由于不懂相关的技术业务,无法理解该类的存在意义(官方解释:A user can save bulk memory copy operations using a composite buffer at the cost of relatively expensive random access.)。这两个类从逻辑上似乎完全可以继承于DerivedByteBuf,Trustin大神为啥如此设计呢?
4、简要的ByteBuf的实现机制

ByteBuf有两个指针,readerIndex和writerIndex,用以控制buffer数组的读写。读逻辑较为简单,不考虑边界的情况下,就是return array[readerIndex++];。这里简要分析一下HeapByteBuf的读逻辑。
- AbstractByteBuf.ensureWritable(minWritableBytes);
- calculateNewCapacity(writerIndex + minWritableBytes)
2.1 判断是否超过可写入容量 maxCapacity – writerIndex
2.2 超过则抛异常,否则计算新容量 writerIndex + minWritableBytes
2.3 判断是否超过设定阈值(4MB),超过每次增加按阈值(4MB)递增,否则
2.4 初始大小为64字节(newCapacity),新容量超过newCapacity则翻倍,直到newCapacity大于新容量为止
2.5 返回Min(newCapacity, maxCapacity); - UnpooledHeapByteBuf.capacity(newCapacity);
3.1 确保可访问,有一个引用计数的机制,引用计数为0,则抛异常(ensureAccessible)
3.2 常规操作:判断是否越界
3.3 如果newCapacity比原容量大,则直接创建新数组,并设置。否则
3.4 如果readerIndex小于新容量,将readable bytes拷贝至新的数组,反之将readerIndex和writerIndex均设置为newCapacity。 - setByte(writerIndex++, value)
4.1 确保可访问
4.2 设置
5、ByteBuf特殊机制
5.1 Pooled
4.x开发了Pooled Buffer,实现了一个高性能的buffer池,分配策略则是结合了buddy allocation和slab allocation的jemalloc变种,代码在io.netty.buffer.PoolArena。暂未深入研读。
官方说提供了以下优势:
- 频繁分配、释放buffer时减少了GC压力;
- 在初始化新buffer时减少内存带宽消耗(初始化时不可避免的要给buffer数组赋初始值);
- 及时的释放direct buffer。
当然,官方也说了不保证没有内存泄露,所以默认情况下还是采用的UnpooledByteBufAllocator。5.x还处于beta版,看它的「new and* noteworthy」文档也没说有啥变化,哈哈哈哈,查看最新的「new and noteworthy」文档,PooledByteBufAllocator已经设置为默认的Allocator。
5.2 Reference Count
ByteBuf的生命周期管理引入了Reference Count的机制,感觉让我回到了CPP时代。可以通过简单的继承SimpleChannelInboundHandler实现自动释放reference count。SimpleChannelInboundHandler的事件方法如下,在消费完毕msg后,可以AutoRelease之:
1 | public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { |
这一小节可以单独拎出来和Pooled放在一起深入研读研读,有兴趣的可以先看看官方文档:Reference counted objects
5.3 Zero Copy
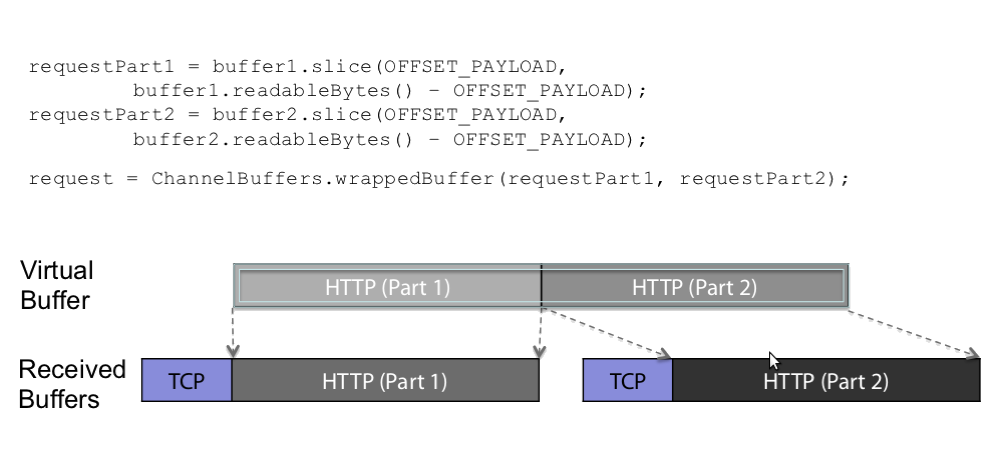
Zero-copy与传统意义的zero-copy不太一样。传统的zero-copy是IO传输过程中,数据无需中内核态到用户态、用户态到内核态的数据拷贝,减少拷贝次数。而Netty的zero-copy则是完全在用户态,或者说传输层的zero-copy机制,可以参考下图。由于协议传输过程中,通常会有拆包、合并包的过程,一般的做法就是System.arrayCopy了,但是Netty通过ByteBuf.slice以及Unpooled.wrappedBuffer等方法拆分、合并Buffer无需拷贝数据。
如何实现zero-copy的呢。slice实现就是创建一个SlicedByteBuf对象,将this对象,以及相应的数据指针传入即可,wrappedBuffer实现机制类似。