
Apache Hadoop YARN - 背景及概述
虽然yahoo!关于YARN作为下一代(Next-gen)MapReduce框架的文章(点这里)去年就看过了,但是那个看到是“下一代”,竟然以为只是一个设想,没想到早就发布了版本,导致对于Hadoop的认识还停留在0.20×版本上,真是罪过罪过。由于最近比较忙,闲暇时间扫了扫国内外博客,发现0.23、1.×,以及最近发布的2.×,hadoop的变化非常之大。比如说HDFS Federation(联邦)支持多NameNode并存,也有HA的BackupNode,想多了解的可以看这里以及官方文档。最大的莫过于计算框架了,MapReduce进入了2.0时代,MR2.0或者叫YARN(其实YARN和MapReduce没什么关系了),这篇博客就简要的说说Apache Hadoop MapReduce的前世今生吧。主要是翻译了这篇博客:地址,也加上了自己的一些见解,后续再继续添加对YARN的认识。
Apache Hadoop MapReduce
Apache Hadoop MapReduce是一个Google MapReduce编程模型的开源版本,由Apache基金会维护。现在,已经有人花了超过6年的时间在Hadoop上。但是,基本上MapReduce基本上可以分为三个主要部分:
- MapReduce API:提供给终端用户(程序猿)开发MR程序的接口;
- MapReduce 框架:MR各个过程(phrase)的实现,如:map phrase、reduce phrase、sort/shuffle/merge phrase等;
- MapReduce 系统:运行用户MR程序的后端基础设施,用以管理资源、调度任务等。
将MR分成以上三个概念非常的重要,特别是对终端用户,他们可以完全专注于MR逻辑代码的编写,只需要通过API既可,由MR系统来解决资源管理、容错、调度的问题,而不需要用户考虑后端框架和系统的细节。
现在工业界大部分还是用的0.23之前的版本(至少我待的公司还是0.20.2),老版本的MapReduce系统是简易的Master-Slaves结构,具体名字叫JobTracker-TaskTracker。
JobTracker负责资源的管理(结点资源、计算资源等)以及任务生命周期管理(任务调度、进度查看、容错等)。而TaskTracker职责非常简单,开启/销毁任务,向JobTracker汇报任务状态。
旧版的架构其实挺清晰的,不过也有很多不足的地方,业界一直嚷着要给MR一次大整修(Overhaul),JobTracker的可靠性是一直被诟病的一点(虽然我没见它挂过,但是风险一直存在着),但是除了JobTracker的单点问题,其它的问题也需要一一列出来。
不支持其它编程模型
MapReduce对大多数应用(尤其是大数据统计分析)来说,都非常合适。但是有的时候,可能现实生活也有其它的编程模型,如图算法(Google Pregel/Apache Giapah)或者是迭代式模型(MPI)。当企业的所有数据在放在了HDFS上,有多种处理数据的方式就很重要了。
而且,MR本质上是面向批处理的,并不支持实时或接近实时的处理请求,但是业界也希望Hadoop能支持实时计算。(我也一直希望可以支持实时计算,但是有时候觉得有点贪心,专注做一项不就好了么?但是好像人的贪欲是无穷的)
有了以上的需求,为了降低了管理者使用成本,减少数据在HDFS和其它存储设备的迁移,Hadoop开发组织重新投入了Hadoop设计。
低可扩展性
摩尔定律一直在生效,也让商用服务器的性能一直提高,以下就是一台商用服务器在不同时间的配置:
- 2009 - 8 cores, 16GB of RAM, 4*1TB disk
- 2012 - 16+ cores, 48-96GB of RAM, 122TB or 123TB of disk
按照上面的配置,大约2-3年,服务器的配置就可以翻翻。而现在的Hadoop集群就只能支持10,000个节点和200,000个核。Hadoop软件需要赶上硬件的速度是非常重要的。顺带说句,我们公司的计算型服务器就是16cores 64GB of RAM。
服务器的低利用率
在现在的系统中,JobTracker将管理集群视为很多的Map/Reduce槽(slot),然而在MR用运行的时候,大多数时候都是reduce槽在等待map槽完成(map 100% reduce 0%)。如果能优化这个的话,服务器就可以得到最大的利用。
使用的灵活性
在现实生产环境中,Hadoop常常被部署成一个共享的、多用户的系统。这样就会导致一种情况,完全Hadoop软件可能会影响到整个部门。用户希望能够控制hadoop软件栈升级,因此,允许多版本的MapReduce框架并存对Hadoop来说就是很重要的了。
Apache Hadoop YARN
YARN的基本思想是将JobTracker的两个主要职责给解耦:资源管理和任务管理(监控/调度),YARN将其分成了两个部分:全局的ResourceManager(RM)和给每个应用分配的ApplicationMaster(AM)。ResourceManager和它每个节点的slave——NodeManager(NM),形成了一个全新的、用以管理应用的分布式系统。
RM是系统资源的终极管理者,而AM则是一个特定应用框架的实体(每次提交任务的时候,需要编写相应的应用框架,现在只支持MapReduce),需要与RM索要应用资源,和NM一起执行和监控任务。
RM中有调度器,而调度器内嵌有策略可插拔的插件,主要负责将集群中得资源分配给多个队列和应用。当前MapReduce的调度器,如Capacity Scheduler和Fair Scheduler,均可作为该插件。但是调度器的职责仅限于调度任务,并不保证任务的容错性。
NodeManager有点类似于TaskTracker,它负责启动应用程序Container(类似于JVM),并监控container的资源(CPU、内存、磁盘、网络等),并将信息上报给ResouceManager。需要注意的是,调度器就是根据应用程序的Container进行调度的。
ApplicationMaster负责向调度器请求合适的container,并监控container的状态以及任务进程。
下图是YARN的架构图:
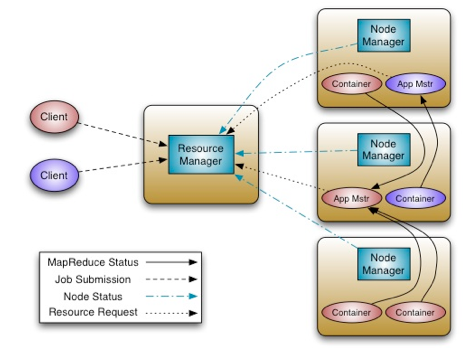
新YARN系统比较重要的一条就是复用了原有的MapReduce框架,而并不需要大的改动,这对现有的MR应用以及用户来说,是非常重要的,具体是怎么复用的,以后再细说。
接下来,Hadoop开发者会深入架构细节,继续提高系统的可扩展性,并让其支持更多的数据处理框架(graph, MPI)并提高集群可用性。
以Hortonworks’ Arun Murthy(YARN开发者)的一段话做结尾吧:
“People are not going to be comfortable buying a $5 million Hadoop cluster just to do MapReduce and a $2 million cluster to do something else. If you can allow them to run both apps in the same cluster, its not only easier for you in terms of a CapEx perspective … it’s also easier from an operational perspective because you don’t have to have two separate sets of people managing your clusters or two sets of tools for managing your clusters.”